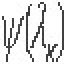
Field Forge™ brings massively parallel processing (MPP) to PostgreSQL’s current single-threaded sessions. Field Forge™ utilizes the MPP power of the Kappa framework. The Kappa framework provides practical usage of CUDA GPU, OpenMP, and partitioned data flow scheduled processing. Field Forge™ make the Kappa framework from Psi Lambda LLC a new Language for defining Window and Table functions. These functions allow processing to be specified using SQL and index component notation for MPP using GPUs and CPUs. Within each Field Forge™ node, the Kappa framework passes (subsets) of the data sets Between processing kernels and into and out of data sets. Field Forge™ also utilizes the Kappa framework’s Apache Portable Runtime (APR) database driver SQL connections to retrieve data fields from any database source (including other Field Forge sessions and nodes), Process Them using the MPP capabilities of the Kappa framework, and return them as PostgreSQL table or window fields returned from table or window functions respectively. This Combination of features enables a Dataset Passing Interface (DPI) for distributed MPP. DPI leverages the existing skills, protocols, connectivity, and infrastructure of an organization.
For data in a database in star schema format or in an OLTP schema, you can use the Kappa framework for high speed, massively parallel processing of the data. The data is transferred in binary form using an extension of the Apache Portable Runtime parameter specification that also specifies the data structure layout for CUDA or OpenMP data structures. If your data is not in a database, you can use existing C, C++, Perl, or Python libraries within the Kappa framework to access the data.
The Kappa framework provides for:
* Transferring with as few processing steps as possible,
* (optional) primary key fields used to specify record selection for reading and updating,
* dimension and measure field support.
